Support for

This article explains the usage of robot.txt files within your w3shop.
Within your main w3shop page you will find a 'robots.txt' panel within the SEO section. This will only display if you have your own domain set.
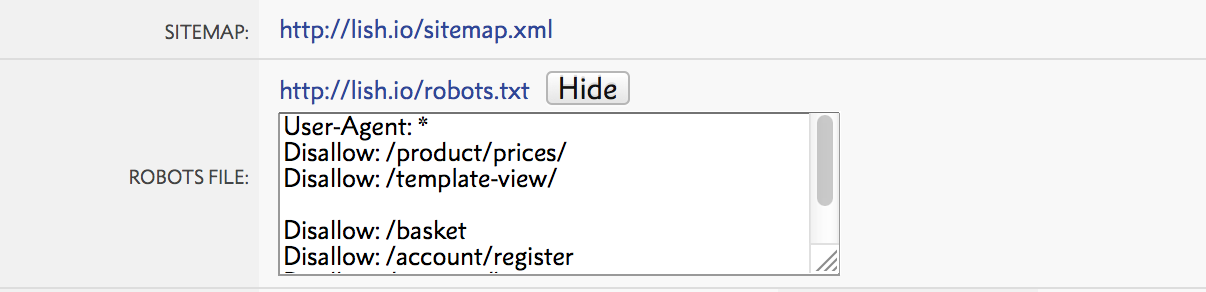
This tells search engine crawlers (Google, bing, yahoo etc) how to visit your site. Importantly what pages or content you do NOT want indexing and therefore where crawlers should NOT visit.
This file is a very simple .txt file. As standard your w3shop robots.txt file will be setup as follows:
User-Agent: * Disallow: /product-price-grid Disallow: /template-details Disallow: /basket Disallow: /account/register Disallow: /account/login
The "User-agent: *" means this section applies to all robots. The "Disallow: /" tells the robot that it should not visit these pages on the site.
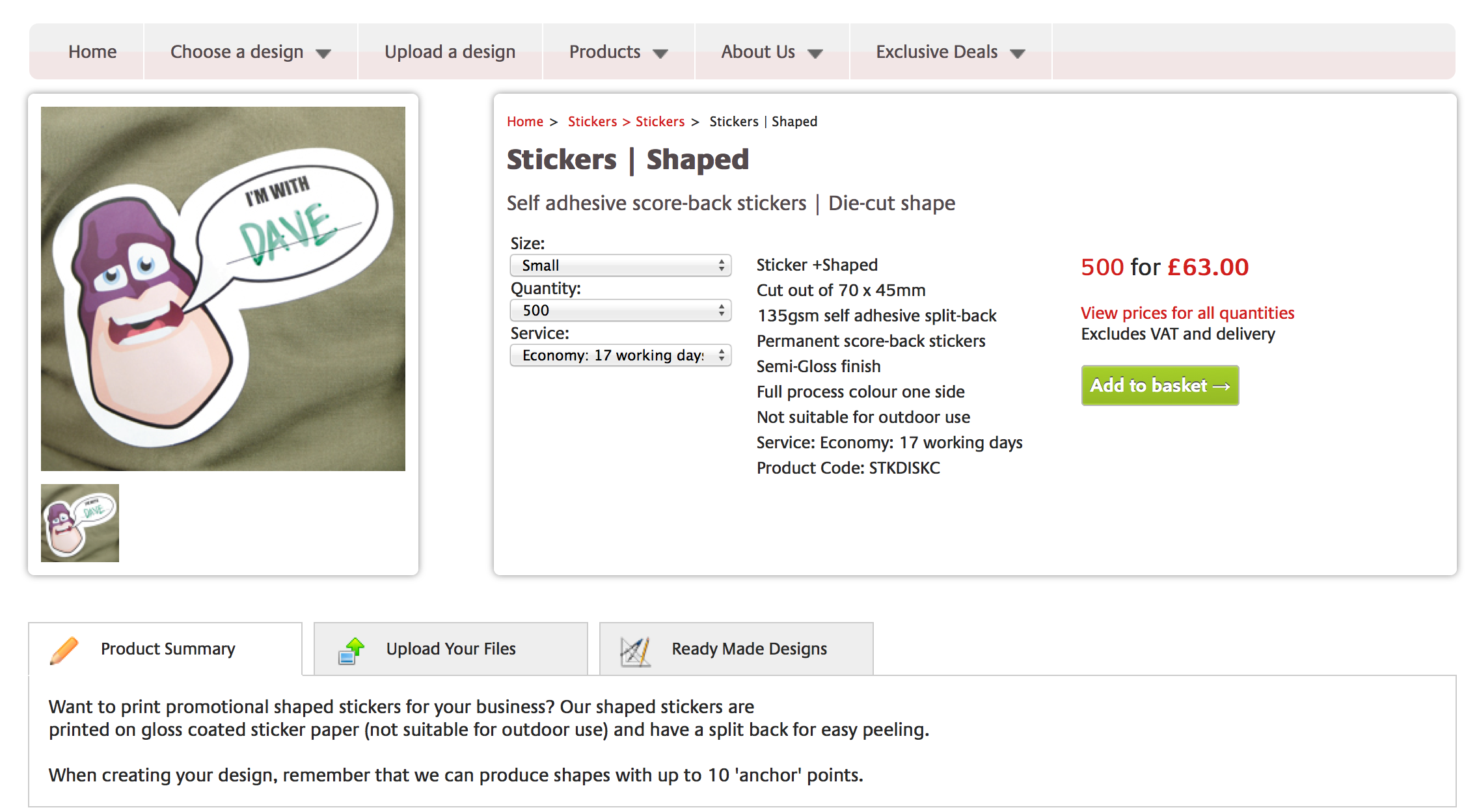
/Product-price-grid (url may vary site by site) is the 'Product price grid' page type. For example, these pages:
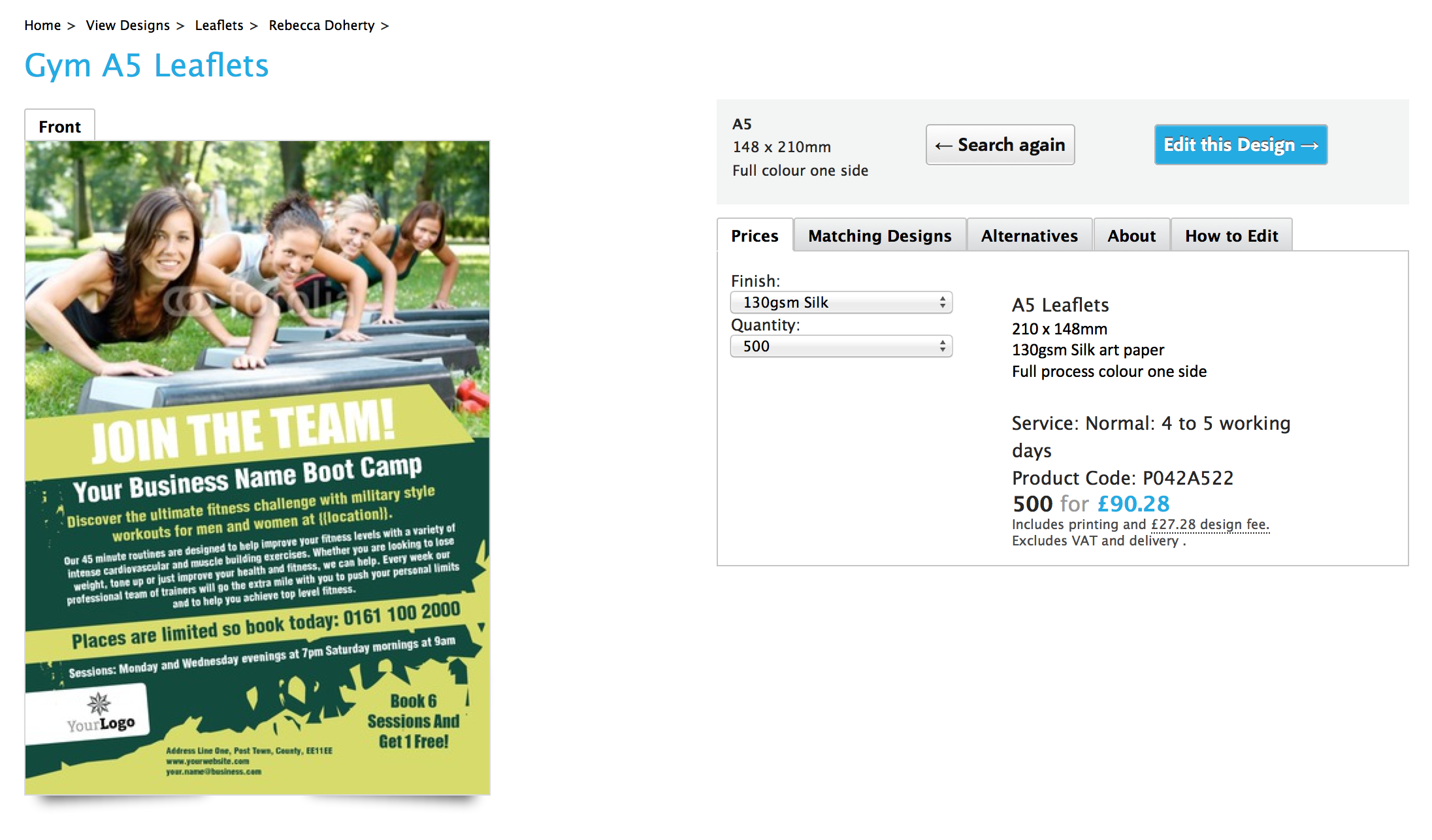
/template-details (url may vary site by site) is the 'Template: details' page type. For example, these pages:
Search engine crawlers have a finite amount of time to crawl your site. If a website has identical content in multiple places, this leaves less time for core pages. This identical content can cause links to be spread across two pages and force the search engine to pick one to display over the other. This shared link value will cause both pages to be weaker than if there was just one core page.
Identical content can be caused by numerous issues, for example:
So using the robots.txt file tells search engines what to focus their time on. Making sure that any potentially duplicate content is avoided by search engines makes it more likely that your core 'Landing Pages' rank on Search Engine Results Pages (SERPs).
Landing pages should be the the focus entry point(s) of your website and therefore what you want to be ranked (along with you main domain).
You can add to, edit or remove elements from the standard robots.txt file. Simply edit the robots file text to add, change or remove the urls listed. You need a separate "Disallow" line for every URL prefix you want to exclude.
Only add this to specific, relevent pages. DO NOT add this to the main category 'header snippet' box.
In addition you may want to use the Meta 'noindex' - a tag added to the of a page. This tells search engines not to index that page. Ideally though, you should be using the robots.txt file because this stores everything in one central location.
However, you can choose to add the Meta 'noindex':
into the header snippet box of the page you want blocked:

If your site has already been indexed and you'd like aspects of you site not to have been, you need to remove any 'disallow' content from your robots.txt file. Then add the Meta 'noindex' to the pages you want de-indexing.
This allows search engines to crawl those pages and see the "noindex, nofollow" tags. Once google has crawled your site again, and de-indexed the relevant pages you can add the disallow content back to the robots.txt file.
See also
|
|||||
Jump to contents page of
|
|||||